支持的提供商
统一枚举 Provider,无需为不同 API 分别写适配器;本地 + 云可混合(例如 Ollama
+ OpenAI)。
一个API客户端,多个提供商:可靠流式处理、函数调用、推理大模型与可观测性 — SDK开销<1ms。
双许可证 MIT / Apache-2.0 · 专注生产级抽象 · 无供应商锁定
单一抽象覆盖 OpenAI / Groq / Anthropic / Gemini / Mistral / Cohere 等。
便捷的图像和音频内容创建,支持 `Content::from_image_file()` 和 `Content::from_audio_file()`。
标准增量格式,隐藏底层 SSE 差异。
内置支持 Groq Qwen、DeepSeek R1 等推理大模型,提供结构化输出。
重试 / 超时 / 分类错误 / 代理 / 连接池。
性能 / 成本 / 健康 / 加权路由。
SDK 层额外延迟 ~0.6–0.9ms(基准方法透明)。
从 quick_chat 到自定义传输/指标按需扩展。
ai-lib-pro 提供高级路由、可观测性、安全性和成本管理功能。
添加依赖后,可使用统一的API立即调用任意受支持的提供商。
[dependencies]
ai-lib = "0.4.0"
tokio = { version = "1", features = ["full"] }
futures = "0.3"use ai_lib::prelude::*;
#[tokio::main]
async fn main() -> Result<(), AiLibError> {
let client = AiClient::new(Provider::Groq)?;
let req = ChatCompletionRequest::new(
client.default_chat_model(),
vec![Message {
role: Role::User,
content: Content::new_text("你好,世界!"),
function_call: None,
}]
);
let resp = client.chat_completion(req).await?;
println!("回答: {}", resp.choices[0].message.content.as_text());
Ok(())
}# 设置API密钥
export GROQ_API_KEY=your_groq_api_key
export OPENAI_API_KEY=your_openai_api_key
export ANTHROPIC_API_KEY=your_anthropic_api_key
# 代理配置(可选)
export AI_PROXY_URL=http://proxy.example.com:8080use ai_lib::prelude::*;
// 从文件创建图像内容
let image_content = Content::from_image_file("path/to/image.png");
// 从文件创建音频内容
let audio_content = Content::from_audio_file("path/to/audio.mp3");
// 混合内容消息
let messages = vec![
Message {
role: Role::User,
content: Content::new_text("请分析这张图片"),
function_call: None,
},
Message {
role: Role::User,
content: image_content,
function_call: None,
},
];use futures::StreamExt;
let mut stream = client.chat_completion_stream(req).await?;
while let Some(chunk) = stream.next().await {
let c = chunk?;
if let Some(delta) = c.choices[0].delta.content.clone() {
print!("{delta}");
}
}
统一枚举 Provider,无需为不同 API 分别写适配器;本地 + 云可混合(例如 Ollama
+ OpenAI)。
以下指标为 SDK 自身层(排除模型推理)。详情见仓库 README。请使用你的实际工作负载再行基准验证。
提示:真实场景受提供商速率限制与网络影响。数值并非保证,仅供参考。
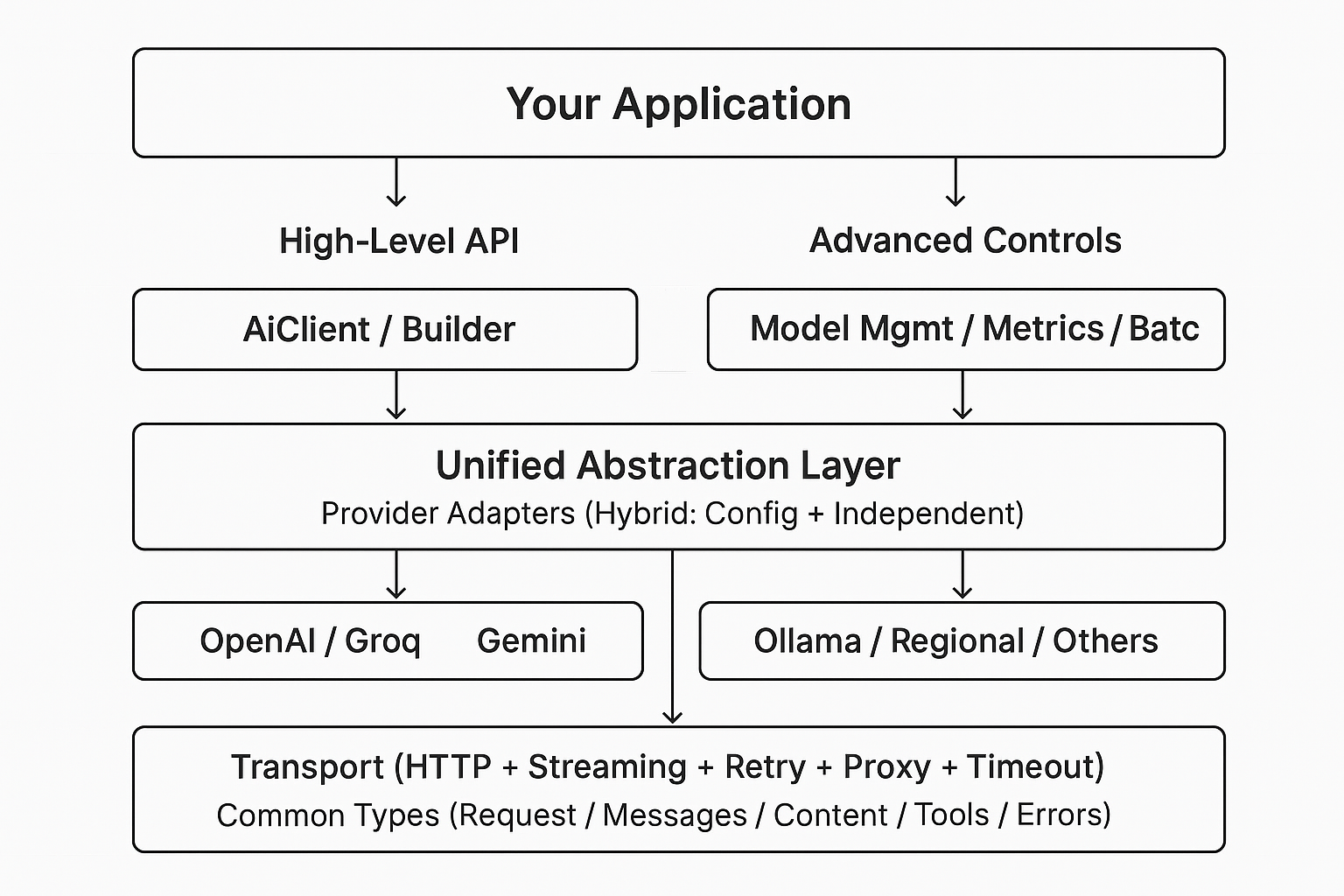
分层设计:应用 → 高级 API → 统一抽象 → 提供商适配器 → 传输(HTTP/流式 + 可靠性)→ 通用类型。
当前阶段:征集早期使用反馈与企业级需求。欢迎联系我们获取演示与合作方案。